
Photo by Myriam Jessier on Unsplash
Scanning (or crawling) is the process of a bot like Google visiting a page and saving the page’s copy to a search engine’s database. The process of saving and organizing the data obtained from scanning is called indexing.
Since a page cannot be displayed in the SERP if it’s not indexed, it’s vital to make sure the page can be indexed and has enough value to do so. There is also a straightforward correlation between domain authority and how often a page is crawled: popular pages can be scanned several times a day. This leads us to the conclusion that by improving the website’s crawlability and indexability, you also improve the overall domain quality.
How Do Crawlability and Indexability Affect the Website?
The number of crawled and indexed pages may not seem like an important metric, but it definitely shows how Google treats websites. If all submitted pages are crawled regularly and the majority of them get indexed, it means the website has good authority and trustworthiness.
There are many parameters that impact crawlability and indexability, such as total page count, traffic, backlink profile, and much more. In this article, we will focus on the technical aspects of a website using SE Ranking’s audit tool to detect issues and affected pages that a search bot might not be able to crawl or index.
Crawlability
Crawlability is the ability of a search engine spider to access your site and includes how often and how many pages it visits. It’s more important than you may think: If there are any obstacles for the crawler, not only does the crawling become slower, but the overall domain quality becomes worse.
The main reasons why a page cannot be crawled are:
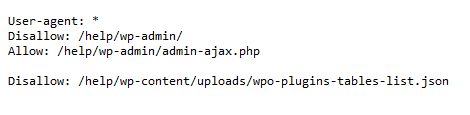
- Blocked in robots.txt
This file contains a set of rules for bots that they should follow.
If a page’s URL contains a disallowed path, the Google bot won’t visit it, so you need to make sure any important pages aren’t blocked in the robots.txt file.
- Isn’t presented in the sitemap and/or doesn’t have ingoing links
To visit your page, Google needs to discover it beforehand. The easiest way to notify search engines about your pages is by submitting a sitemap. The sitemap is a file with a list of URLs on your site. If you use CMS or online store builders like Wix or Shopify, they should generate a sitemap automatically or with the plugin.
Another way to tell Google about your page is through internal linking: google bots crawl not only the page but also all outgoing internal links.
Crawl budget
This term refers to how many resources Google dedicates to crawl the site. It’s relevant for big sites (1M+ pages) and is not measured in dollars or any other metric. You want to increase your crawling budget because then your pages will be crawled and indexed much more frequently.
To not overload servers, Google monitors how your site handles crawling. If it starts responding with a delay or with 5xx/4xx, Google stops crawling to prevent your site from going down. So checking status codes is a basic part of a website audit that is helpful in terms of crawlability and indexability.
Indexability
This parameter tells if a search bot is able to index your website and how many of your crawled pages are actually indexed. Indexing is the process of saving a copy of a page to the search engine’s database. After the Googlebot visits the page, it evaluates whether the page is worthy of being indexed to appear in search results. If the page was crawled, but not indexed, it means it has one of the following issues:
- “Noindex” meta tag
If the page contains a “noindex” robots tag, it’s a directive for the search engine not to store its copy.

- Duplicated content
If page content is the same as another indexed page, it will be considered as duplicated content and therefore might not get indexed on your website. Be careful: content can be duplicated not only inside your domain but across all websites on the web.
- Canonical to another page
If URL 1 has rel=”canonical” to URL 2, URL 1 won’t be indexed because it’s pointing to URL 2 as the original version. Also, if there are more than two copies of a page, all of them should be pointing to the same URL, otherwise, there will be several canonical versions of one page.
- Non-200 response code
3xx, 4xx, and 5xx pages are not indexed because they bring zero value to the user. A static non-200 page is not only bad, but if the server response is not consistent, the page can be excluded from Google’s index.
- Low-value content
Speaking of value, pages with bad content won’t be indexed either – I doubt you store trash, and neither does Google. “Bad content” is a very broad term, which includes practices like text spinning, keyword stuffing, low-volume content, etc.
- Page performance
Users don’t like to wait too long. UX metrics also impact the overall page quality, so if a page’s performance is bad, the page may be excluded from indexing.
Remember: regardless of the issue, if the search engine encounters any problems crawling or indexing your website, it will make your website less trustworthy.
How to check Crawlability and Indexability Issues?
One of the oldest technical SEO optimization tools is ScreamingFrog. It will show all the main errors your site has, but you need to start it manually and it might be hard to make conclusions and a proper action plan based on the data you get.
There are some better solutions nowadays which we’ll now discuss.
Google Search Console
Not so long ago, Google released a Coverage report for the Search Console. It features data on both crawling and indexing.
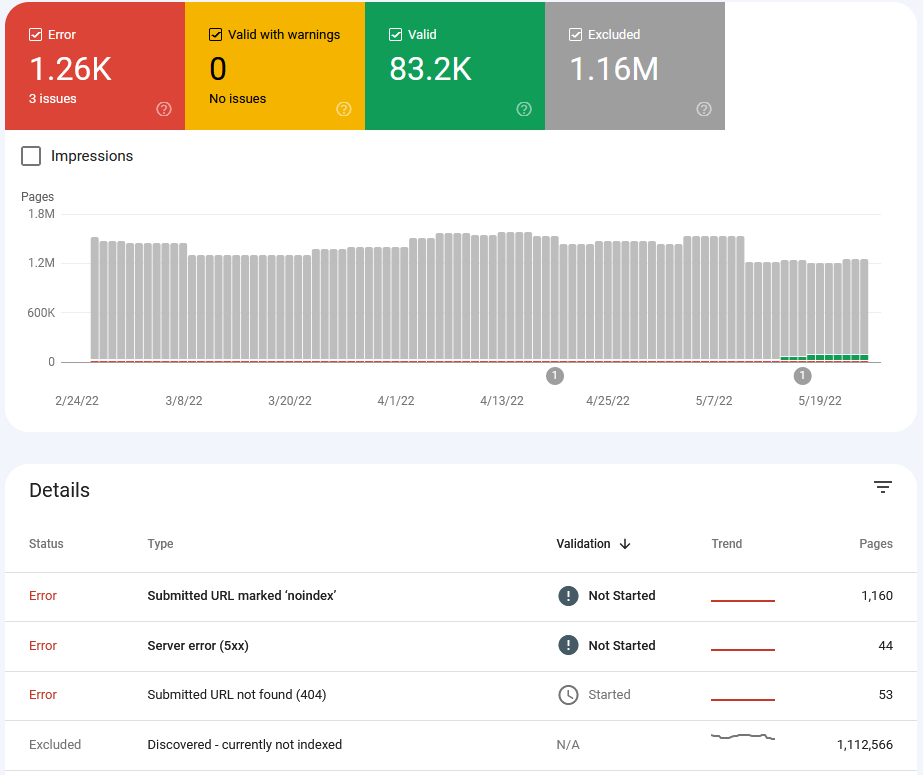
From this report, you can see discovered pages, indexed pages, and errors. The errors report includes non-200 pages and pages blocked for indexation in robots.txt or by the meta robots tag – it’s enough to get the big picture, but fixing issues from this report might be challenging.
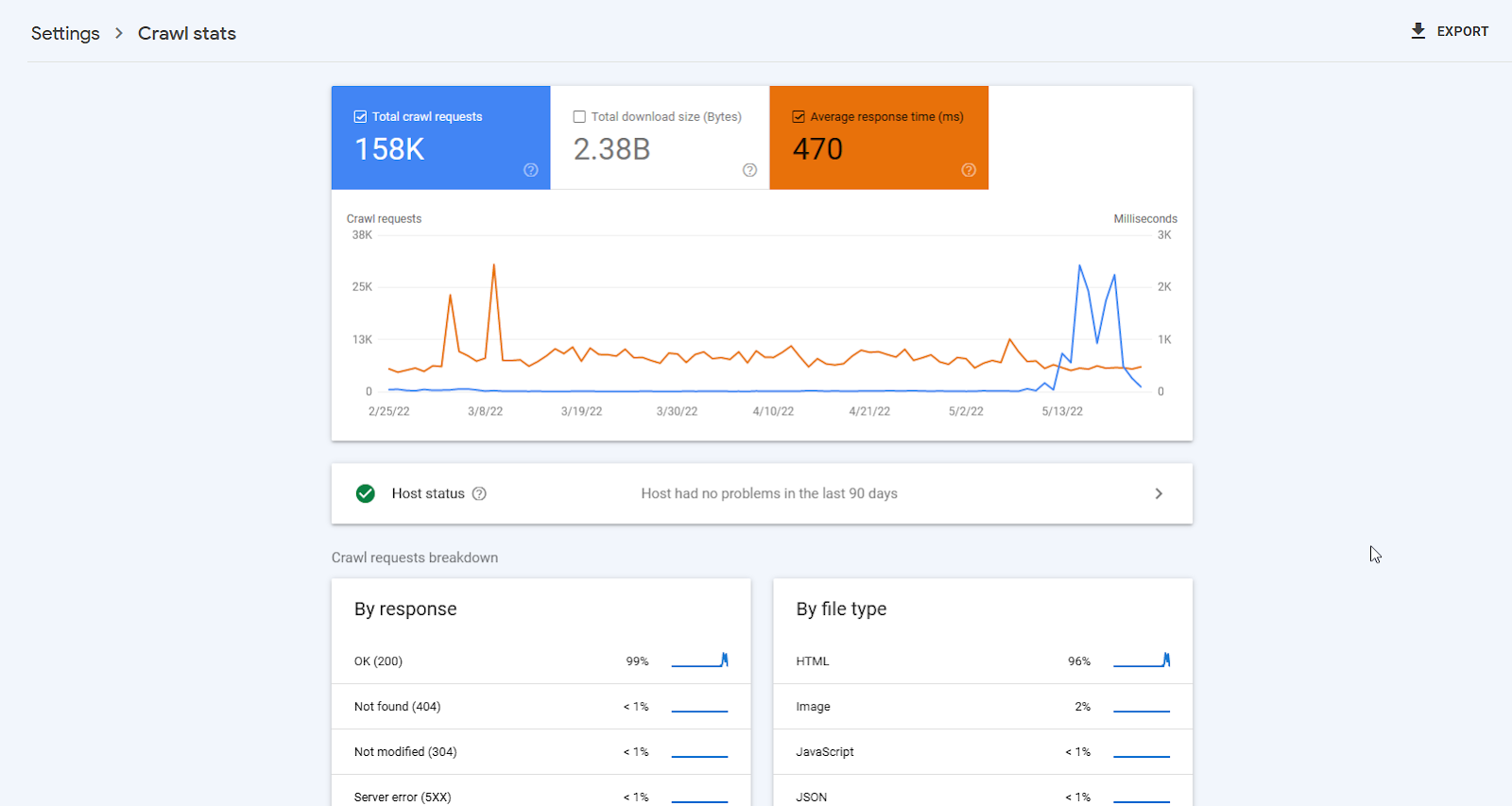
There is also a “Crawl stats” report hidden in the settings. It displays data on how often the Googlebot visits your page. While the Crawling report shows the results of crawling, the Crawl stats are about the process of scanning itself.
While the tool is free, it is not flexible in presenting issues and doesn’t give a clear understanding of how to fix them.
SE Ranking
In terms of technical issues, SE Ranking is much better than GSC.
Not only does it verify hardcore errors but also minor issues, plus it provides instructions on how to fix them – it’s a much more convenient way to improve a website’s crawlability and indexability.
There are 2 types of reports that improve a website’s crawlability and indexability:
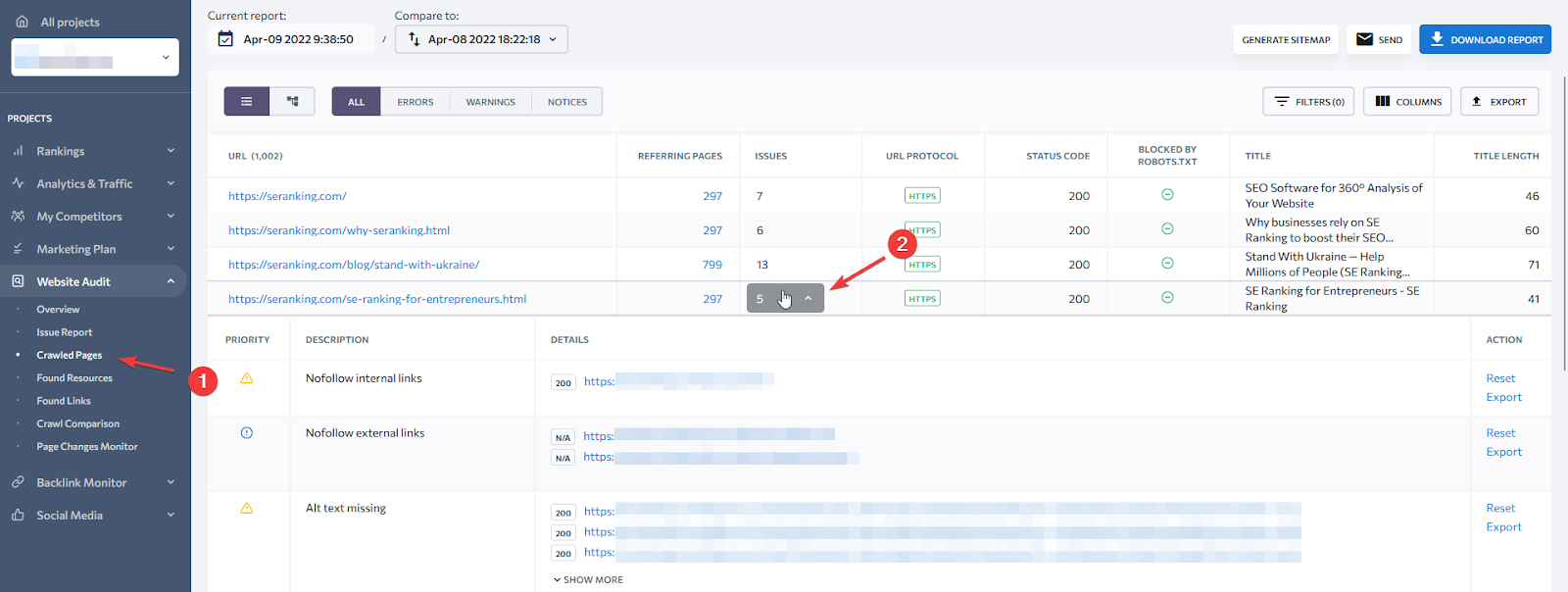
- URL-driven (“Crawled Pages”)
This method works best to check and improve important pages.- Go to Crawled Pages to see the list of URLs found on your website
- You can access issues the page is having by expanding the list.
- Issue-driven (“Issue Report”)
This approach focuses on solving top-priority and frequently occurring errors – this method is most suitable for fixing issues of the whole domain because problems are oftentimes not page-unique, so fixing a single URL will also fix the problem across other pages with the issue. To follow this approach, go to the Issue Report tab.
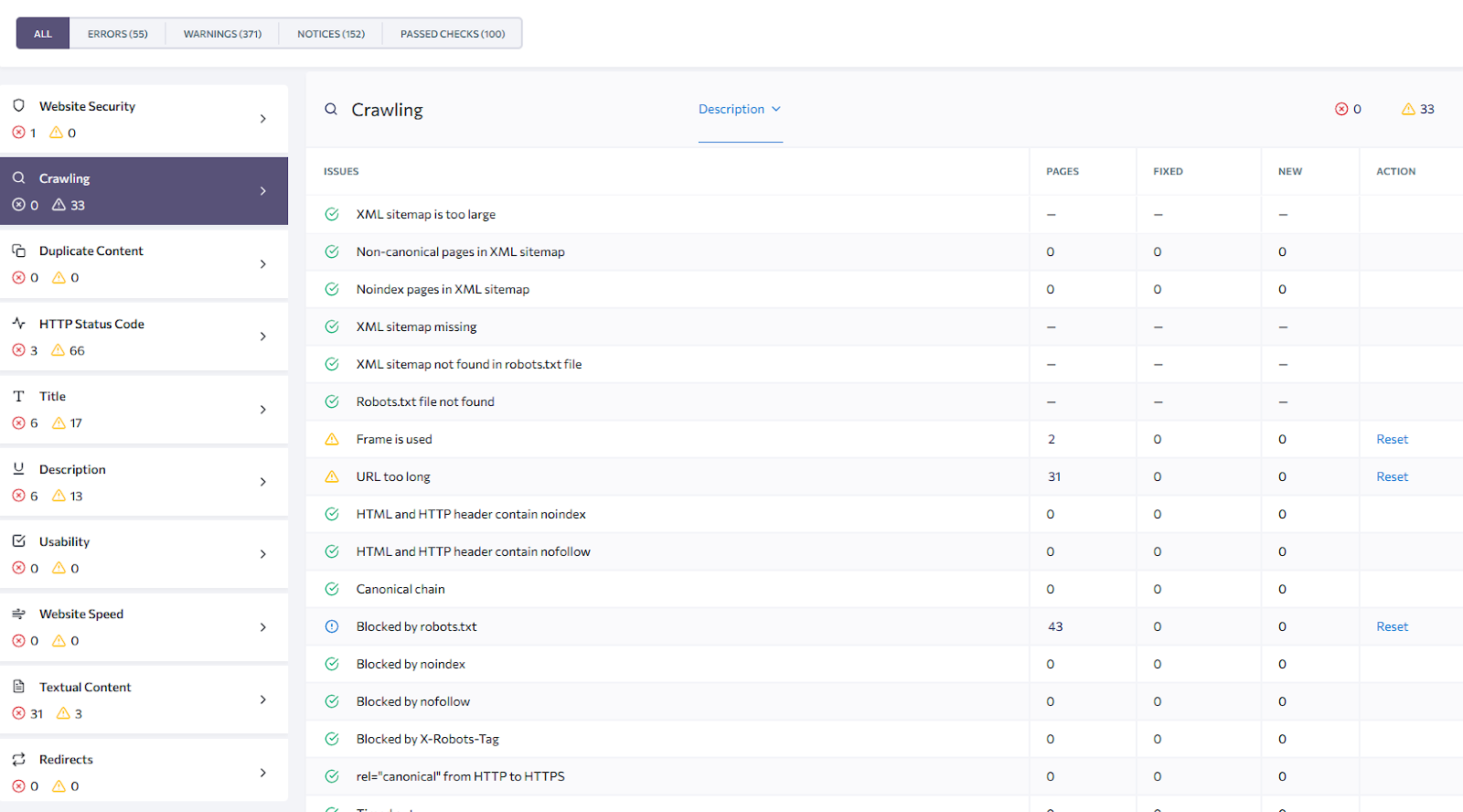
Main Crawlability and Indexability Issues for Monitoring
Let’s dive deep into SE Ranking to see how to fix technical issues. Applying these fixes not only makes it easier for Google to crawl and index your website, but also improves the overall quality of the domain, which leads to a gain in positions – basically, by implementing SE Ranking’s recommendations you are increasing traffic.
Robots.txt, noindex, and sitemap issues
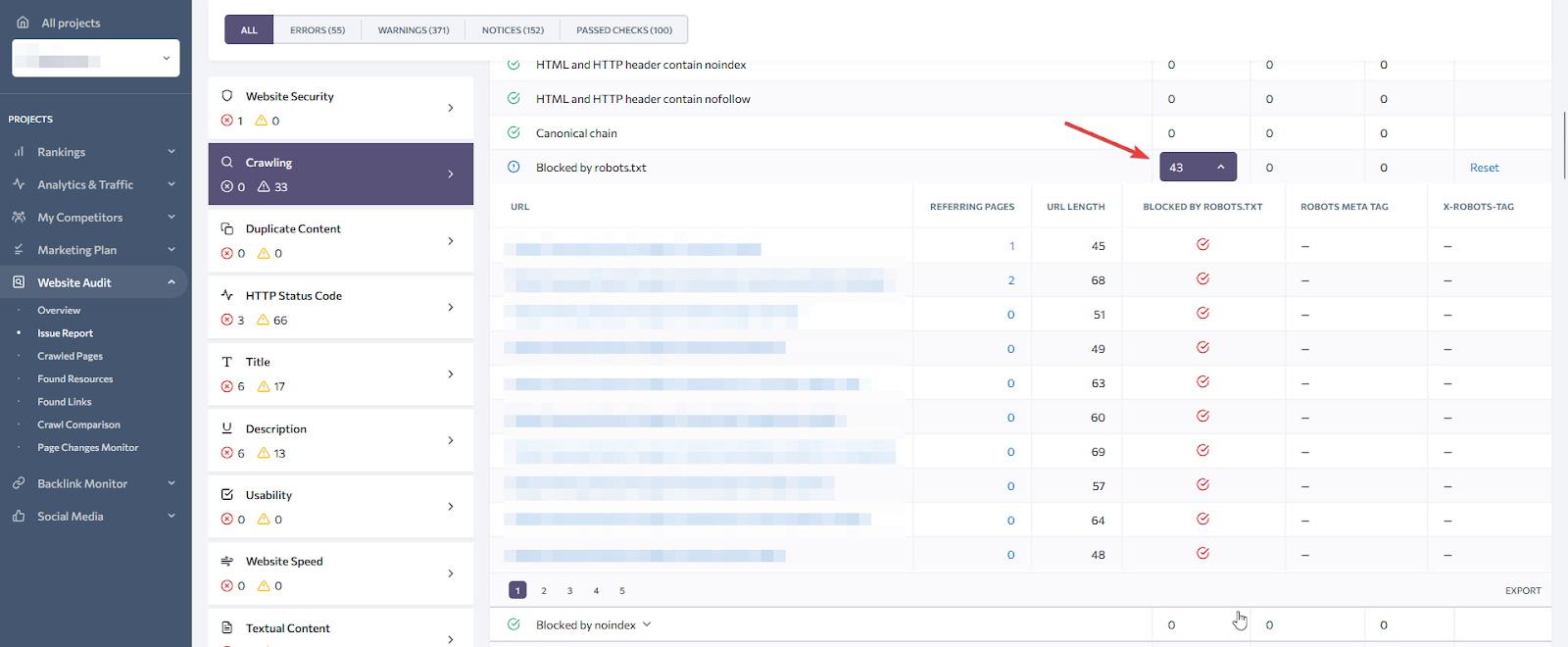
Navigate to “Crawling” in the Issues Report to access the dashboard with all checked issues. If there is an error, you can expand the list of pages affected by it and even export it. In this example, we see all pages that are blocked from bots visiting in the robots.txt file. Besides this issue, you can examine pages that are blocked via the “noindex” tag or not presented in the sitemap.
Redirects and broken pages
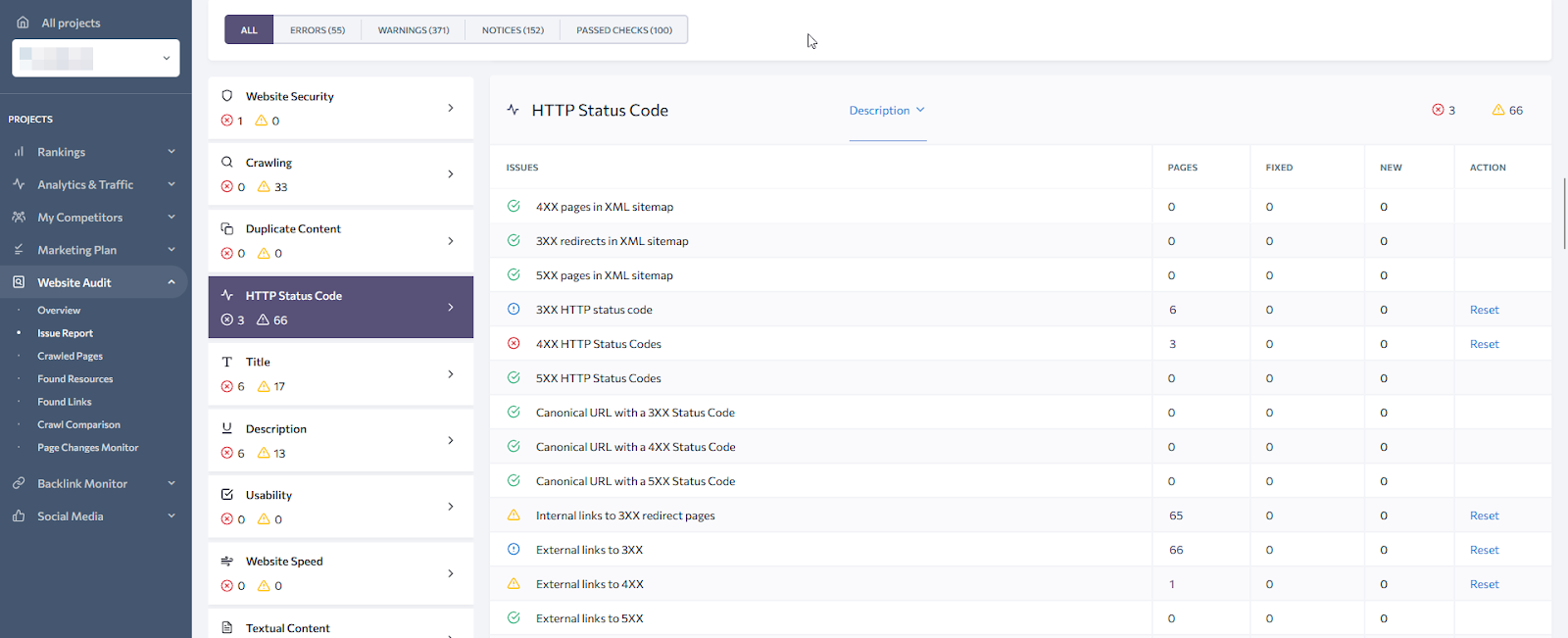
Making all pages respond with 200 codes is a fundamental task of technical optimization. With the HTTP Status Code report, you are able to see all issues associated with non-200 pages. Whether it is an internal link to the 404 page or a hreflang to 301, SE Ranking will display all found issues, along with their pages.
Internal Linking
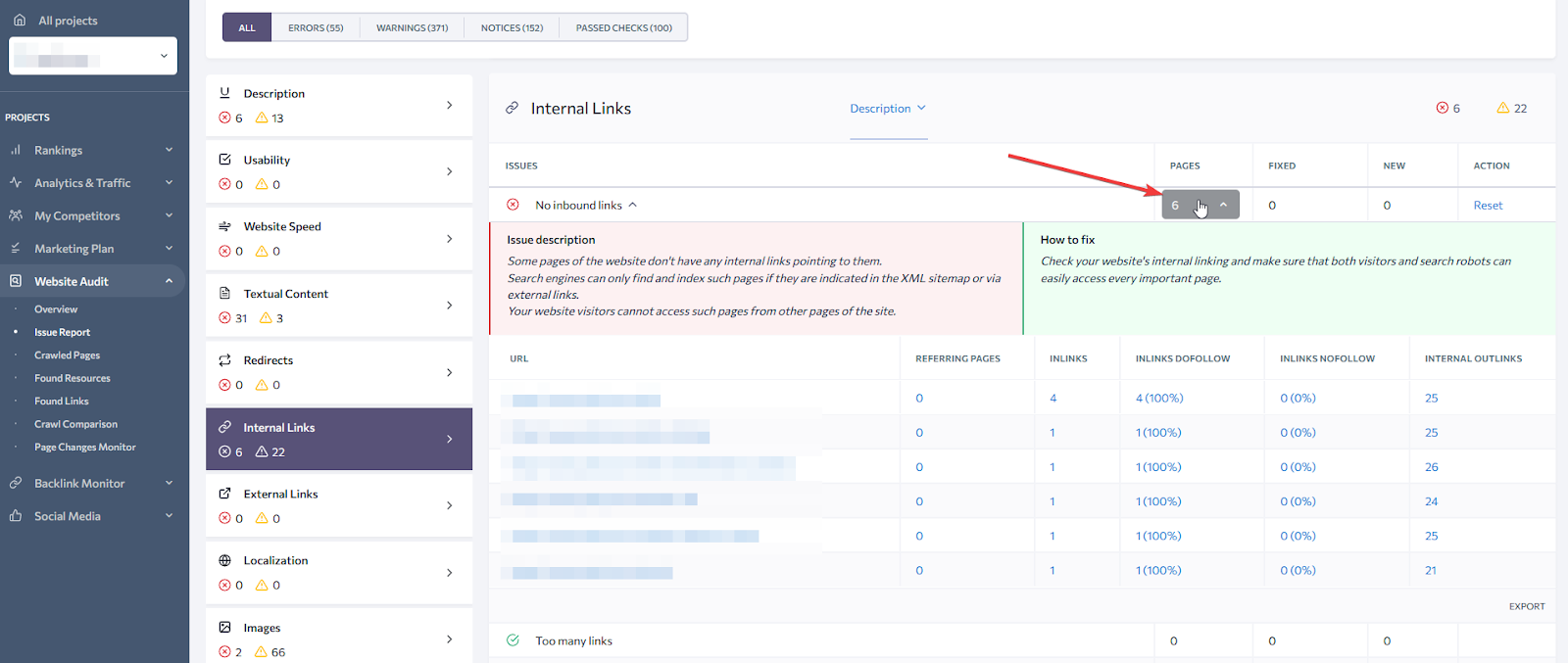
Internal links are not only a way of discovering new pages, but also a great tool to signal the importance of a page to Google: if a page receives many inbound links, it improves its priority and the chances of it being crawled and indexed. The best practice is to have all pages with a minimum of 1 inbound link, so make sure you have no “orphan” pages.
Duplicate content and canonical tags issue
Duplicated content is not always a bad thing, sometimes it’s just how the site works. For example, for an e-commerce website a single product can be assigned to several categories with different URLs, but the content is identical – the same page with a different URL. Yet all copies have to point to a single original document – the canonical one. If identical pages have no canonical link or the link is for a different URL, those pages are considered duplicated and might be not indexed.
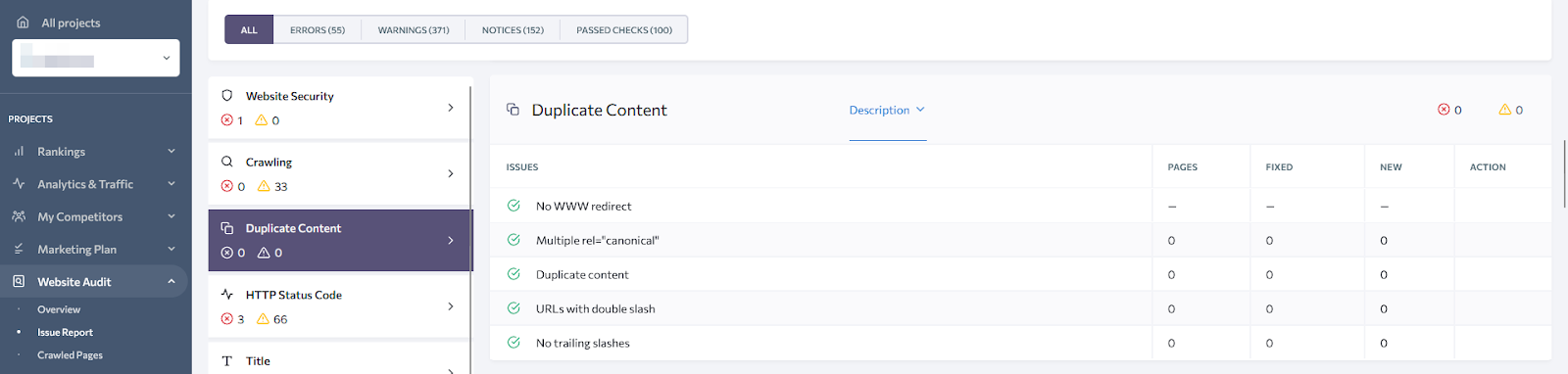
To make sure this is not the case with your site, visit the “Duplicated content” section. Ideally, you should have no issues.
Website speed and performance
Loading speed has a great impact on user experience and overall page quality, so by increasing the performance it’s possible to make a page more attractive for indexing.
The Website Speed report consists of several tests. The first one is for the overall loading time while crawling: pages that load in more than 3 seconds are considered as slow, because after this threshold the bounce rate greatly increases.
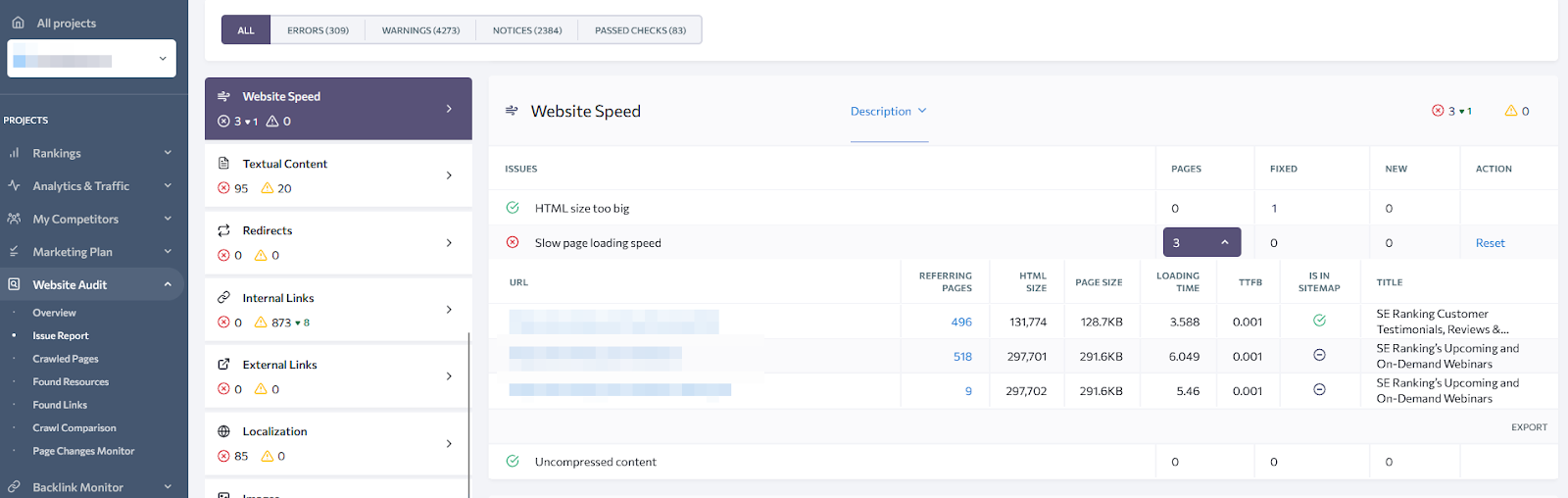
That’s a synthetic test, meaning the measurements were made with good internet and hardware. In reality, many users have much slower connections and/or weak devices. That’s why it’s important to see the metrics from the users.
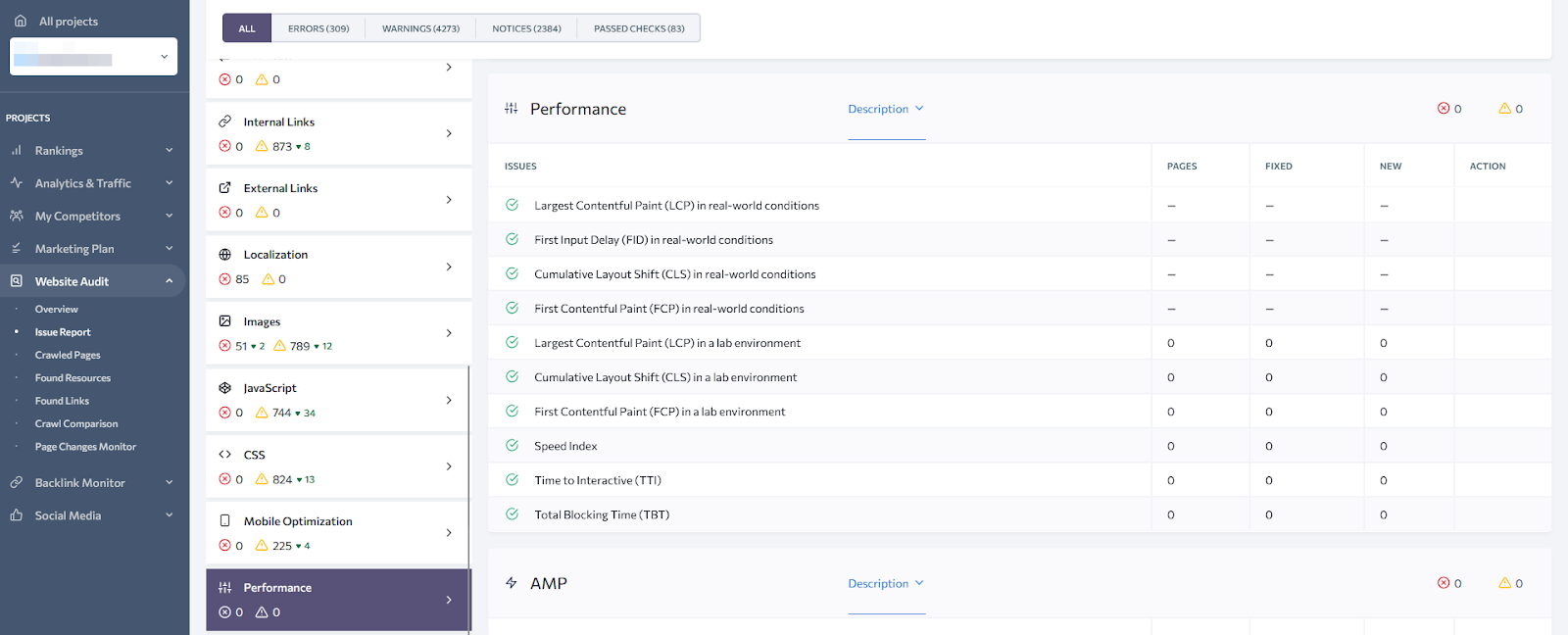
The Performance report is made specifically for this. It measures Google’s Web Vitals metrics emulating a slow 3G connection.
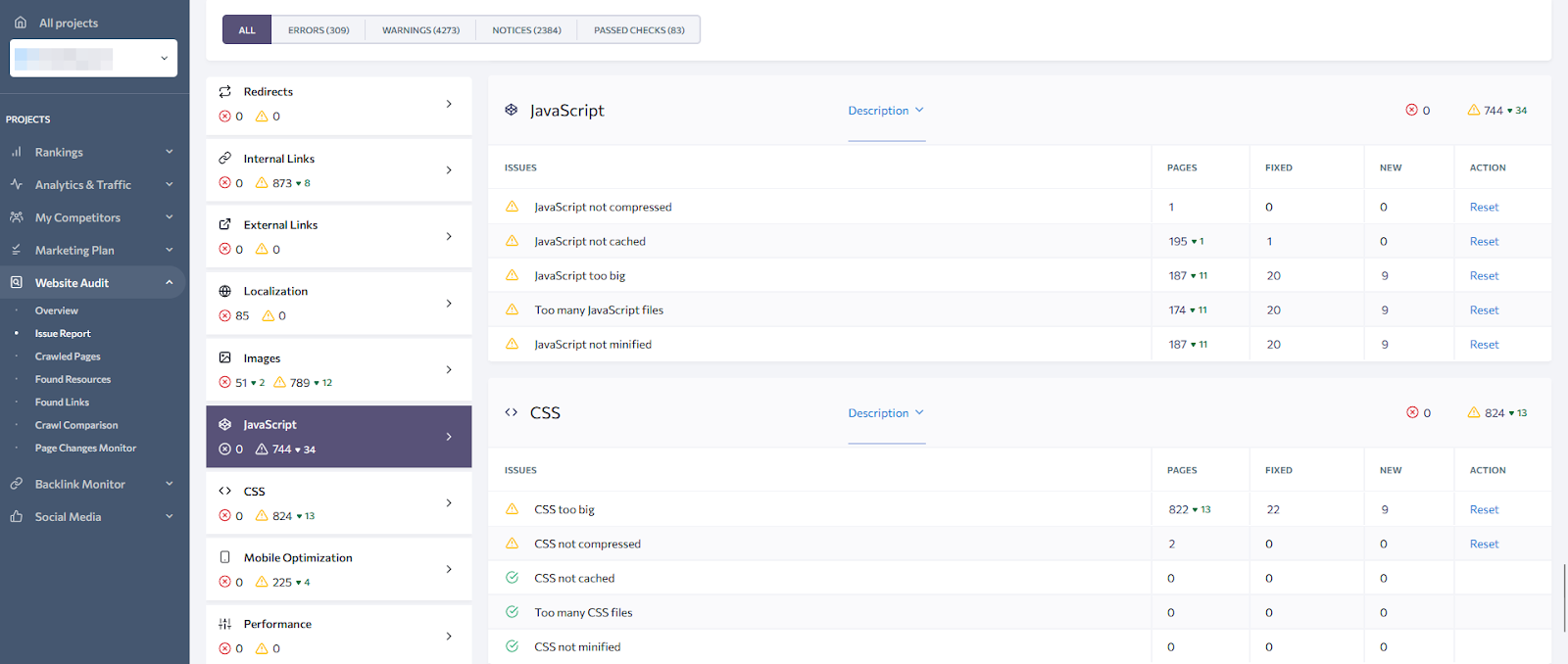
Last but not least are JS and CSS optimization reports. Using them, you can generate a clear technical assignment for the front end developers – export affected pages with recommendations on how to fix them
Content Issues
We’ve mentioned that sometimes pages may not be indexed due to poor content. Content quality is an arguable topic, but there are a few fundamentals that should not be ignored. All of them are included in the “Textual content” tab – make sure you fix important issues there.
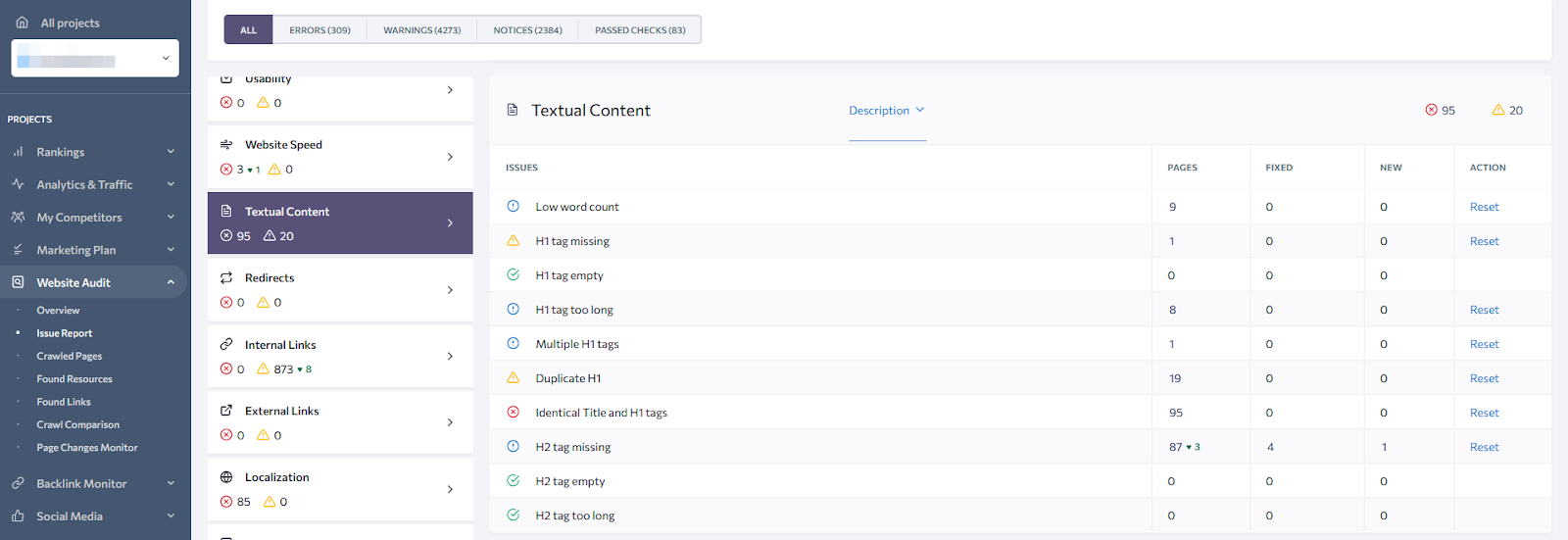
Also, fixing content issues might help you with rankings–for example, when you improve both the H1 and Title tag for your focus keyword without making them identical.
Wrapping up
Remember the following: if the page hasn’t been crawled, it cannot be indexed. If the page is not indexed, it cannot appear in the search results. If the page is not presented in the search results, it cannot receive organic traffic.
And making sure that search bots can access your website successfully gives you far more than just improved crawlability and indexability. Treat bots as your guests, and make them enjoy visiting you so they want to come back. This way you gain trust from Google, which will surely be reflected in your positions.